
k8s 动手实现成组调度 GangScheduling
本文为 unicore 实现的一部分,为 mcyouyou 提供一些高级 k8s 实践功能。功能设计参考阿里云 coscheduling 插件实现。
需求背景
众所周知 k8s 的调度单位是 pod。然而,现在很多批处理或 ai 任务等负载都由多个可扩展的 pod 组件构成,这些负载都有一个 all or nothing 的属性,即要么都部署成功,要么全部 pending,不能只部署单独几个 pod,避免无法整体提供服务还挤占集群资源,甚至导致资源死锁。例如,现在 ai 推理负载的典型架构 pd 分离,将 LLM 推理分成 prefill 和 decode 两部分在分别的机器上部署,就必须要分成多个 pod,并成组进行部署。
目前 k8s 还没有对成组调度的官方支持。因此,在 k8s 的调度层面需要实现一种成组调度(Gang Scheduling),实现一套调度器插件,对原生调度器进行扩展,实现 all or nothing 的调度。
背景知识
k8s 的调度器在设计上是单点的,因为调度器把关集群的资源分片,所以必须是原子的。因为不能实现多个调度器,所以 k8s 对调度器的扩展性是通过调度器插件来实现的。
首先 k8s 调度框架定义了一系列扩展点,如下面这个非常经典的图:
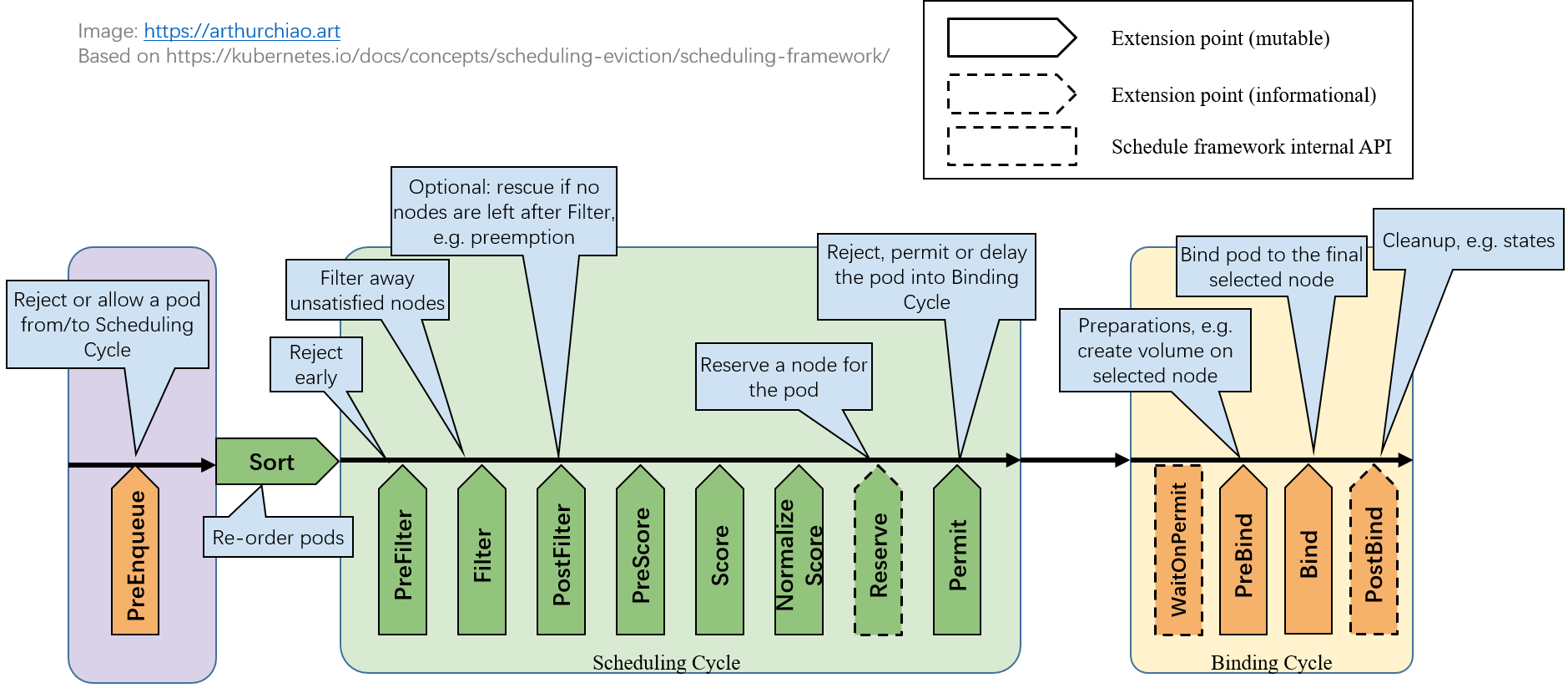
调度器插件将调度过程分为两个阶段:
- scheduling cycle:为 pod 选一个合适的 node
- binding cycle:将上述调度结果落库
同时,在开始一轮调度前,pod会先进入调度队列,也可以在这里完成扩展对待调度 pod 进行排序。
下面就结合调度过程来看看各个扩展点的含义。官方文档:Scheduling Framework | Kubernetes
等待阶段
PreEnqueue:
-
决定 pod 能否从 ready for scheduling 状态进入调度队列
-
输入:pod 信息的封装;输出:对 pod 的决定
QueueSort:
-
对调度队列的 pod 进行排序
-
输入:两个 pod 信息的封装;输出:Less()比较的结果
调度阶段
PreFilter:
-
pod 预处理和过滤,可以预处理或筛掉不符合预期的 pod。任何一个插件返回失败则 pod 被排除。
-
输入:v1.Pod;自定义保存的状态信息,可在后面的扩展点使用;输出:对 pod 的决定
Filter:
-
node 过滤。针对所有 node,调度器按配置顺序执行 filter plugins,任何一个插件返回失败则 node 被排除。
-
输入:node 信息;输出:对 node 的决定
PostFilter:
- 如果所有 node 都被 Filter 过滤,执行这个阶段进行补救。按 plugin 顺序依次执行,任何一个插件将 node 标记为 schedulable 就为成功。
- 典型例子:抢占
preemption插件,在这个阶段挑一个 pod 的资源来抢占。 - 输入:pod 信息、node 筛选信息;输出:PostFilter 的决定结果
PreScore:
- 打分预选,计算打分用的中间数据
- 输入:Pod、可选 node 列表;输出:中间数据 *Status
Score:
- 打分,针对每个 node 依次调用 scoring plugin,得到一个分数。分数是每个插件打分的加和。
- 输入:pod、node;输出:打分
NormalizeScore:
- 归一化打分,可以对打分结果反向、加权、标准化等
- 输入:所有节点打分结果;输出:调整后的打分结果
Reserve:
- 这个阶段起通知作用(Informational),不影响调度决策。提供了两个方法调用:
Reserve和Unreserve。前者用来告知插件要保留某node给某pod,所有插件返回成功后调度循环才会继续;后者是调度失败回滚时执行,必须幂等不能 fail。 - 这个阶段是为了保证 需要维护状态的插件(Stateful Plugin)及时更新,避免和 scheduling cycle 并行的 bind cycle 操作结束前因为冲突导致问题,确保整个调度的原子性。
Permit:
- scheduling cycle 最后的把关点,可以允许、阻止或延迟 pod 进入 binding cycle
- 输入:pod、node;输出:三种结果:允许、拒绝(触发 unreserve)、等待(设置的超时时间)。
- 所有插件批准 pod 后进入绑定阶段;如返回等待,则超时前将不会重新进入调度循环,而是加入内部等待队列,直到有插件手动批准。等待超时后 pod 将被拒绝。
绑定阶段
PreBind:
- Bind 之前的预处理,可以挂 volume 等前置操作。任何一个 prebind 插件失败,都会导致 pod 被 reject,触发上面的 unreserve。
- 输入:pod、node;输出:*Status
Bind:
- 正式的 bind 操作,按配置顺序调用全部插件,但最多只有一个插件处理 bind。如果插件选择跳过,由下一个插件继续处理;如果返回失败,pod 会被 reject。
- 输入:pod、node;输出:*Status
PostBind:
- bind 成功的 pod 进行一些收尾操作,如清理临时文件,informational,不影响调度决策。
- 输入:pod、node;没有输出。
设计
Pod 标识
这里采用一个自定义的 label gang.unicore.mcyou.cn/name 来标识需要成组调度的 pod 对应的组名,同一个组的 pod 调度必须成组保证。这样可以支持多个组同时参与调度。同时设置 gang.unicore.mcyou.cn/available-count 表示这个组允许一次同时下发的最小 pod 数(设为组内的预期 pod 数)。
成组等待
成组调度最重要的就是实现一个全有或全无的机制。这个机制的实现可以利用调度循环的最后一个环节:permit。这个扩展点下我们可以利用延时等待,让一个组的 pod 在全部抵达 permit 前保持等待,全组到达后再放行到最后的 binding 阶段。这样,只有一整个组全都完成了资源预占,可以下发到节点时才会整组下发,在整组都预占完成前则不会实际占用节点资源。
调度前处理
至此,已经可以保证实际把 pod 下发到节点是成组的。但有两个问题:
在 permit 阶段时 pod 已经过了 reserve 阶段,已经在调度器 cache 中预占了资源。因此如果多个组同时进入调度循环,或非编组的 pod 混在组内进入调度循环,都可能造成资源被抢占或死锁。
另外,如果一个组的 pod 还没全部进入调度队列就放行进入 reserve 阶段,也会导致其他 pod 混入组间,产生和上面一样的问题。
因此,需要在两个方面做一些改进:
- 为调度队列实现一个自定义排序,确保正确将同组的 pod 在队列中放在一起。这样就不会有外组夹杂干扰 reserve。这点可以通过 QueueSort 扩展点自定义排序规则实现。
- 在进入队列的 pod 开始调度前的 PreFilter 扩展点,可以将尚未全组入队的 pod 直接拒绝,不让其进入本次调度。注意,这里考虑当前的 pod 数量时,除已进入调度队列的,还要加上已 running 的,保证幂等。
这样,进入调度循环的 pod 都是整组且连续的;而经过前面的实现,绑定到节点的过程也是整组且连续的。
绑定前回退
目前为止可以(尽可能)保证所有组的 pod 在进入调度循环,以及实际绑定到节点都是整组且连续的。但是这和 all or nothing 还是有差距——假如组内的 pod 预分配到一半资源不够了,那这组 pod 就肯定无法整组调入本集群了。这时候就需要将在调度循环中已预占资源的 pod 进行回退。
由于我们在之前保证了 Permit 阶段会延缓全组 pod 的绑定,所以在 Permit 阶段应计算其已等待的时间,如有 pod 超时,则将整组的 pod 全部拒绝,避免其部分 pod 一直占用资源影响其他 pod 或 pod 组调度,实现 “nothing” 的部分。
局限
上面的设计可以保证在集群用户视角下,pod 一旦下发到节点,就是整组或全部 pending 的。这是因为 Permit 阶段的严格把关,对整组 pod 的放行是原子的,非成组 pod 根本没有机会进入绑定循环。
但是这样的设计也有一些局限,即在资源紧张时,仍然有可能因为成组 pod 同时下发而导致组之间互相死锁,即使我们已经采取一些措施减少死锁的可能性。这是因为我们虽然用了额外的设计修改了调度队列的排序和放通,使其尽量以成组的形式进入调度循环,但因为无法区分 pending pod 是否真的进入了调度队列(ActiveQ),而不是还未入队或在其他Q中,因此在 prefilter 阶段并不能保证全组原子进入调度循环。这样,还是有可能导致调度循环中的 pod 顺序不成组,在预占资源阶段形成死锁。不过,死锁情形下由于不能通过 permit 卡点,死锁的两组 pod 都会在超时后被清理出调度循环,避免长期死锁,也算是一定程度上解决了问题。
另外,在绑定阶段如果出现异常(如存储卷绑定异常),插件也没办法正确感知,使得组内可能有部分 pod 绑定失败。不过这种情况属于 pod 下发后的异常,和调度策略本身无关了。
实现
下面开始实现这个调度器插件。作为一个 out-of-tree 的调度器插件,它本身是作为一个独立的 go 程序存在的,并且由一个独立的 docker 容器来运行。大概项目结构长这样:
├── cmd
│ └── main.go
└── pkg
└── plugin
└── gang
└── gang.go
[!NOTE]
需要注意的是,由于调度器框架本身使用到了 k8s 的代码(如调度器的服务端 cmd 等),因此要么将其和本地下载的 k8s 代码放在一起编译,要么用 replace 的方式指定远程仓库版本。
这里推荐直接使用官方的 scheduler-plugins 项目的 go mod 文件,避免自己 replace 的各种问题:scheduler-plugins/go.mod at master · kubernetes-sigs/scheduler-plugins
main 函数
调度器插件是独立运行的程序,因此首先实现一个 main 函数:
package main
import (
"schedule_plugin/pkg/plugin/gang"
"k8s.io/component-base/cli"
"k8s.io/klog/v2"
scheduler "k8s.io/kubernetes/cmd/kube-scheduler/app"
"os"
)
func main() {
klog.Info("starting unicore-scheduler..")
command := scheduler.NewSchedulerCommand(
scheduler.WithPlugin("unicore-gang-scheduler", gang.New))
code := cli.Run(command)
os.Exit(code)
}
整套调度器插件利用 k8s.io/kubernetes/cmd/kube-scheduler/app 来启动、加载配置并管理插件,完成 handler 实现对扩展点的调用。main 函数中,我们注册名为unicore-gang-scheduler的插件,传递一个框架要求格式的 New 方法,返回一个调度器插件实例。由于调度器的使用是互斥的,为了弥补一个 pod 只允许指定一个调度器,这里框架其实允许同时注册多个调度器插件,这里只注册 unicore-gang-scheduler 一个。
插件直接返回了一个 *cobra.Command,因此用 k8s 的公共方法或者直接调自带方法启动都是可以的。
插件结构
接下来我们实现插件结构。framework.Plugin 接口本身只要求一个 Name() 方法,具体实现什么方法要根据需要实现的扩展点来决定,并实现对应的接口。
type GangScheduler struct {
podLister listerv1.PodLister
handle framework.Handle
firstGangPodCreatedAt sync.Map
firstGangPodPermittedAt sync.Map
permittedGangPods sync.Map
rejectedGangs sync.Map
mu sync.Mutex
}
var _ framework.PermitPlugin = &GangScheduler{}
var _ framework.QueueSortPlugin = &GangScheduler{}
var _ framework.PreFilterPlugin = &GangScheduler{}
var _ framework.ReservePlugin = &GangScheduler{}
func (g *GangScheduler) Name() string {
return "unicore-gang-scheduler"
}
根据上面的设计,我们需要实现 Permit、QueueSort、PreFilter、Reserve 四个扩展点。因此我们写一个显式实现,确保对应方法正确实现。
在创建插件时,框架会传入插件可查看的数据和工具方法。例如,我们下面就需要 handle.SharedInformerFactory() 提供的 pod lister 来实现对集群 pod 的拉取,并通过 handle 提供的方法来遍历 Permit 扩展点的等待队列。
func New(_ context.Context, _ runtime.Object, handle framework.Handle) (framework.Plugin, error) {
klog.Info("starting unicore-gang-scheduler..")
g := &GangScheduler{
podLister: handle.SharedInformerFactory().Core().V1().Pods().Lister(),
handle: handle,
}
go g.CleanUp()
return g, nil
}
Permit
实现最关键的 Permit 扩展点。Permit 需要识别整个调度过程中已经到达 permit 阶段节点的 gang pod 数量,将未满足的置于等待队列,直到满足数量要求后整批允许进入 binding 阶段。
我们拆开 pod 的生命周期来看,上述目标要求我们识别:
-
已下发但未进入 Permit 阶段的 pod
-
被 Permit 插件置于等待队列的 pod
-
被 Permit 插件批准,但未完成 binding 的 pod
-
完成 binding 的 pod
其中,1. 可以通过 pod 状态处于 pending 来识别;2. 则可以通过 handler 提供的迭代 waiting list 的方法来获取;4. 这种 pod 则会被设置为 running 状态。
而 “被 Permit 插件批准,但未完成 binding 的 pod”不能通过其自带状态来区分,需要插件在自身状态中进行统一维护。这样,我们的调度器就变成了“有状态插件”。
维护一个有状态插件,需要:
- 并行的扩展点需要加锁
- 自行管理状态信息的储存和释放
- 有较大影响的关键状态要持久化
对成组调度插件来说,我们采用一个“类 session”的形式设计,而非绑定一个 etcd 存储的 CR,所以这里不进行状态持久化,但并发加锁、状态的存储和释放管理是一定要做好的。
[!WARNING]
调度器的整个流程虽然是串行的,但这是对单个 pod 来说的。实际上多个 pod 同时进行调度,是执行了多个调度工作流,并发调用调度器插件。因此对于有状态插件来说,必须处理好并发竞态。
我们给插件结构体引入 permittedGangPods 这个 sync.Map,在 permit 一个 pod 之后记录。下次触发 Permit 扩展点时,通过将记录值减去 Running pods 的交集,即可得到已 Permit 但尚未 Running 的 pods 了。
接下来, 处于等待队列、已 Permit 但尚未 running、已 running 的 pod 分别计数相加,就得到了这个 gang 到达 Permit 的 pod 数量。如果数量未达标签表示的定义预期,通过返回的 *framework.Status 信息要求 pod 进入等待队列,并提供一个等待超时时间,这里我们设置为1分钟。如果数量已达标签预期,允许该 pod 以及等待队列中的所有 pod 进入 binding 阶段。
// Permit imply Permit plugin
func (g *GangScheduler) Permit(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) (*framework.Status, time.Duration) {
gangName, availableCount := p.Labels[LabelGangName], p.Labels[LabelGangAvailableCount]
if gangName == "" || availableCount == "" {
return framework.NewStatus(framework.Success, "not gang-pod"), 0
}
_, ok := g.rejectedGangs.Load(gangName)
if ok {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, "gang "+gangName+" has been rejected"), 0
}
runningPods, _, err := g.getRunningAndPendingPodsInGang(gangName)
if err != nil {
klog.Errorf("PERMIT list running pod for gang %v err: %v", gangName, err)
return framework.NewStatus(framework.Error, err.Error()), 0
}
availableCnt, err := strconv.Atoi(availableCount)
if err != nil {
klog.Errorf("PERMIT parse availableCnt for pod %v err: %v", p.Name, err)
return framework.NewStatus(framework.Error, err.Error()), 0
}
waitingPods := g.getWaitingPodsInGang(gangName)
permittedButNotRunningPods := 0
permittedPods, ok := g.permittedGangPods.Load(gangName)
if ok {
g.mu.Lock()
// add permitted but not running pods
permittedPodsMap := permittedPods.(map[string]bool)
runningPodsMap := make(map[string]bool)
for _, pod := range runningPods {
runningPodsMap[pod.Namespace+"/"+pod.Name] = true
}
for pod := range permittedPodsMap {
if !runningPodsMap[pod] {
permittedButNotRunningPods++
}
}
g.mu.Unlock()
}
if len(waitingPods)+permittedButNotRunningPods+len(runningPods)+1 < availableCnt {
klog.Infof("Permit found not enough gang %v's pod %v, %v waiting + %v permitted + %v running + 1 < "+
"%v available needed", gangName, p.Name, len(waitingPods), permittedButNotRunningPods, len(runningPods), availableCnt)
return framework.NewStatus(framework.Wait, fmt.Sprintf("waiting for pod count to reach availableCnt %v: %v waiting, %v running",
availableCnt, len(waitingPods), len(runningPods))), time.Minute
}
// permit the entire gang
klog.Infof("Permit allow gang %v's pod %v, allowing the entire gang for %v waiting + %v permitted "+
"+ %v running + 1 >= %v available needed",
gangName, p.Name, len(waitingPods), permittedButNotRunningPods, len(runningPods), availableCnt)
g.mu.Lock()
defer g.mu.Unlock()
g.handle.IterateOverWaitingPods(func(pod framework.WaitingPod) {
if pod.GetPod().Labels[LabelGangName] == gangName {
pod.Allow(g.Name())
g.setPermittedInPodMap(gangName, pod.GetPod())
}
})
g.setPermittedInPodMap(gangName, p)
return framework.NewStatus(framework.Success, "gang availableCnt meet: "+fmt.Sprintf("%d",
len(waitingPods)+permittedButNotRunningPods+len(runningPods)+1)), 0
}
[!NOTE]
由于我们对状态的考虑是基于 label 和 pod 到达的事件,而不是有一个 CR 负责维护状态和预期,这里引入一个“session 超时”,也就是一个 gang 的所有状态信息将在最后一个 pod 进入调度后的一段时间清除,确保占用的内存能够被回收。因此我们期望用户的成组 pod 应当是一次性下发,且组名称不应重复。
Less
Less 扩展点实现了 QueueSort 插件。这里的目标:
为调度队列实现一个自定义排序,确保正确将同组的 pod 在队列中放在一起。这样就不会有外组夹杂干扰 reserve。
需要注意同一时间只能存在一个排序规则,因此这里不仅要正确处理组内的 pod 和组间的 pod,还要正确处理非成组的 pod。
排序规则:
- 先创建的 pod 优先;
- 成组的 pod,以当前组第一个进入 less 扩展点的 pod 的创建时间作为整个组的创建时间
- 创建时间相同的组之间比较,按字母序决定
考虑到 pod 的 creationTime 精度只到秒级,所以这里必须按字母序决定同时创建的组的顺序,而不是像默认 pod 一样随机,保证两个组的全部 pod 都能分别排序到一起。
// Less imply QueueSort plugin
func (g *GangScheduler) Less(pod1 *framework.QueuedPodInfo, pod2 *framework.QueuedPodInfo) bool {
gang1, gang2 := pod1.Pod.Labels[LabelGangName], pod2.Pod.Labels[LabelGangName]
time1, time2 := pod1.Pod.CreationTimestamp.Time, pod2.Pod.CreationTimestamp.Time
if gang1 != "" {
fistGangPodTime, ok := g.firstGangPodCreatedAt.Load(gang1)
if ok {
time1 = fistGangPodTime.(time.Time)
} else {
g.firstGangPodCreatedAt.Store(gang1, time1)
}
}
if gang2 != "" {
fistGangPodTime, ok := g.firstGangPodCreatedAt.Load(gang2)
if ok {
time2 = fistGangPodTime.(time.Time)
} else {
g.firstGangPodCreatedAt.Store(gang2, time2)
}
}
if time1.Equal(time2) && gang1 != "" && gang2 != "" {
// compare by gang name for gangs created at the same time
klog.Infof("Less comparing names for gang %v's pod %v and gang %v's pod %v: %v",
gang1, pod1.Pod.Name, gang2, pod2.Pod.Name, strings.Compare(gang1, gang2) < 0)
return strings.Compare(gang1, gang2) < 0
}
klog.Infof("Less comparing time for gang %v's pod %v and gang %v's pod %v: %v and %v",
gang1, pod1.Pod.Name, gang2, pod2.Pod.Name, time1, time2)
return time1.Before(time2)
}
PreFilter
PreFilter 扩展点主要解决两个问题:
- 当前 pending 的 pod + running 的 pod 还不够的肯定不能通过 Permit 阶段,直接提前过滤掉等其他组内 pod 排在一起再通过,避免组内混入其他 pod 导致潜在死锁;
- 如果有同组 pod 被其他插件拒绝,进入 unreserve 阶段的,直接视为整组失败拒绝掉。
// PreFilter imply PreFilter plugin
func (g *GangScheduler) PreFilter(ctx context.Context, state *framework.CycleState, p *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
gangName, availableCount := p.Labels[LabelGangName], p.Labels[LabelGangAvailableCount]
if gangName == "" || availableCount == "" {
return nil, framework.NewStatus(framework.Success, "not gang-pod")
}
_, ok := g.rejectedGangs.Load(gangName)
if ok {
return nil, framework.NewStatus(framework.UnschedulableAndUnresolvable, "gang "+gangName+" has been rejected")
}
klog.Infof("gang %v's pod %v entering PreFilter state", gangName, p.Name)
runningPods, pendingPods, err := g.getRunningAndPendingPodsInGang(gangName)
if err != nil {
klog.Errorf("PreFilter list running pod for gang %v err: %v", gangName, err)
return nil, framework.NewStatus(framework.Error, err.Error())
}
availableCnt, err := strconv.Atoi(availableCount)
if err != nil {
klog.Errorf("PreFilter parse availableCnt for pod %v err: %v", p.Name, err)
return nil, framework.NewStatus(framework.Error, err.Error())
}
if len(runningPods)+len(pendingPods) < availableCnt {
klog.Errorf("PreFilter not enough available pod for gang %v, filter out pod %v, %v running + %v pending"+
" < %v available needed",
gangName, p.Name, len(runningPods), len(pendingPods), availableCnt)
return nil, framework.NewStatus(framework.Unschedulable, fmt.Sprintf("not enough available pod for gang %v", gangName))
}
klog.Infof("gang %v's pod %v passed prefilter for %v running + %v pending >= %v available needed",
gangName, p.Name, len(runningPods), len(pendingPods), availableCnt)
return nil, framework.NewStatus(framework.Success, fmt.Sprintf("gang availableCnt meet: %v", len(runningPods)+len(pendingPods)))
}
Unreserve
Unreserve 扩展点属于 Reserve 插件。Unreserve 扩展点本身只做通知作用,告知插件这个 pod 已被拒绝。因此这里更新状态,将整组记为被拒绝,同时拒掉所有还在等待队列里的组 pod。
// Unreserve imply Reserve plugin
func (g *GangScheduler) Unreserve(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) {
gangName, _ := p.Labels[LabelGangName], p.Labels[LabelGangAvailableCount]
if gangName == "" {
return
}
klog.Infof("recieved unreserve event for gang %v's pod %v", gangName, p.Name)
// reject the entire gang
g.mu.Lock()
defer g.mu.Unlock()
rejectCnt := 0
g.handle.IterateOverWaitingPods(func(pod framework.WaitingPod) {
if pod.GetPod().Labels[LabelGangName] == gangName {
pod.Reject(g.Name(), fmt.Sprintf("gang's pod %s is unreserved", p.Name))
rejectCnt++
}
})
g.rejectedGangs.Store(gangName, true)
if rejectCnt > 0 {
klog.Infof("Unreserve rejected %v pods for gang %v, trigger pod: %v", rejectCnt, gangName, p.Name)
}
}
状态清理
由于是有状态插件且不依赖于某个 crd 来迭代,这种类似 session 的机制需要定期清理掉过期的组状态。新的同名组到来时按新的组来处理。
// CleanUp clean up expired gang's states
func (g *GangScheduler) CleanUp() {
for {
time.Sleep(time.Second)
g.mu.Lock()
g.firstGangPodPermittedAt.Range(func(key, value any) bool {
if !value.(time.Time).IsZero() && value.(time.Time).Add(GangExpirationTime).Before(time.Now()) {
gangName := key.(string)
g.firstGangPodPermittedAt.Delete(gangName)
g.firstGangPodCreatedAt.Delete(gangName)
g.permittedGangPods.Delete(gangName)
g.rejectedGangs.Delete(gangName)
klog.Infof("cleaned expired gang %v's states", gangName)
}
return true
})
g.mu.Unlock()
}
}
测试
这里下发一个副本数为3,最小 available 数为2的 deployment 来测试:
apiVersion: apps/v1
kind: Deployment
metadata:
name: unicore-gang-test
labels:
app: unicore-gang-test
spec:
replicas: 3 # 总副本数
selector:
matchLabels:
app: unicore-gang-test
template:
metadata:
labels:
app: unicore-gang-test
gang.unicore.mcyou.cn/name: "test" # 成组调度组名
gang.unicore.mcyou.cn/available-count: "2" # 最小可用副本数
spec:
schedulerName: unicore-scheduler # 指定自定义调度器
containers:
- name: nginx
image: nginx:1.25
注意这里要手动指定 schedulerName 为我们的 schedulerName。
下发后查看调度器的 log,大概如下:
I1026 15:26:45.028587 1 schedule_one.go:99] "Attempting to schedule pod" pod="default/unicore-gang-test-f6567d6fb-lwqgd"
I1026 15:26:45.028740 1 gang.go:111] gang test's pod unicore-gang-test-f6567d6fb-lwqgd entering PreFilter state
E1026 15:26:45.028772 1 gang.go:125] PreFilter not enough available pod for gang test, filter out pod unicore-gang-test-f6567d6fb-lwqgd, 0 running + 1 pending < 2 available needed
I1026 15:26:45.028793 1 schedule_one.go:474] "Status after running PreFilter plugins for pod" pod="default/unicore-gang-test-f6567d6fb-lwqgd" status="not enough available pod for gang test"
I1026 15:26:45.029435 1 schedule_one.go:1044] "Unable to schedule pod; no fit; waiting" pod="default/unicore-gang-test-f6567d6fb-lwqgd" err="0/4 nodes are available: not enough available pod for gang test. preemption: 0/4 nodes are available: 4 No preemption victims found for incoming pod."
I1026 15:26:45.036385 1 schedule_one.go:99] "Attempting to schedule pod" pod="default/unicore-gang-test-f6567d6fb-rcv2h"
I1026 15:26:45.036478 1 gang.go:111] gang test's pod unicore-gang-test-f6567d6fb-rcv2h entering PreFilter state
// pod 通过 preFilter 阶段
I1026 15:26:45.036550 1 gang.go:130] gang test's pod unicore-gang-test-f6567d6fb-rcv2h passed prefilter for 0 running + 3 pending >= 2 available needed
// pod 被阻拦在 Permit 阶段
I1026 15:26:45.037024 1 gang.go:210] Permit found not enough gang test's pod unicore-gang-test-f6567d6fb-rcv2h, 0 waiting + 0 permitted + 0 running + 1 < 2 available needed
I1026 15:26:45.037066 1 framework.go:1498] "One or more plugins asked to wait and no plugin rejected pod" logger="Permit" node="kind-worker3" pod="default/unicore-gang-test-f6567d6fb-rcv2h"
I1026 15:26:45.037126 1 schedule_one.go:99] "Attempting to schedule pod" pod="default/unicore-gang-test-f6567d6fb-9lzm6"
I1026 15:26:45.037184 1 gang.go:111] gang test's pod unicore-gang-test-f6567d6fb-9lzm6 entering PreFilter state
I1026 15:26:45.037201 1 gang.go:130] gang test's pod unicore-gang-test-f6567d6fb-9lzm6 passed prefilter for 0 running + 3 pending >= 2 available needed
I1026 15:26:45.037210 1 framework.go:1523] "Pod waiting on permit" pod="default/unicore-gang-test-f6567d6fb-rcv2h"
// 第二个 pod 到达 Permit,满足要求,放行自身和 waiting 的 pod
I1026 15:26:45.037447 1 gang.go:217] Permit allow gang test's pod unicore-gang-test-f6567d6fb-9lzm6, allowing the entire gang for 1 waiting + 0 permitted + 0 running + 1 >= 2 available needed
I1026 15:26:45.037507 1 schedule_one.go:99] "Attempting to schedule pod" pod="default/unicore-gang-test-f6567d6fb-lwqgd"
I1026 15:26:45.037570 1 gang.go:111] gang test's pod unicore-gang-test-f6567d6fb-lwqgd entering PreFilter state
I1026 15:26:45.037602 1 gang.go:130] gang test's pod unicore-gang-test-f6567d6fb-lwqgd passed prefilter for 0 running + 3 pending >= 2 available needed
// 放行的 pod 进入绑定循环
I1026 15:26:45.037590 1 default_binder.go:53] "Attempting to bind pod to node" logger="Bind.DefaultBinder" pod="default/unicore-gang-test-f6567d6fb-rcv2h" node="kind-worker3"
I1026 15:26:45.037662 1 default_binder.go:53] "Attempting to bind pod to node" logger="Bind.DefaultBinder" pod="default/unicore-gang-test-f6567d6fb-9lzm6" node="kind-worker2"
I1026 15:26:45.037853 1 gang.go:217] Permit allow gang test's pod unicore-gang-test-f6567d6fb-lwqgd, allowing the entire gang for 0 waiting + 2 permitted + 0 running + 1 >= 2 available needed
I1026 15:26:45.037894 1 default_binder.go:53] "Attempting to bind pod to node" logger="Bind.DefaultBinder" pod="default/unicore-gang-test-f6567d6fb-lwqgd" node="kind-worker"
可以看到各个阶段都在达到两个 pod 的最低要求以后才被放行,符合预期。
然后我们再下发一个四个副本的 deployment,同时加上反亲和性,使其每个副本不允许部署到同一节点:
template:
metadata:
labels:
app: unicore-gang-test
gang.unicore.mcyou.cn/name: "test" # 成组调度组名
gang.unicore.mcyou.cn/available-count: "4" # 最小可用副本数
spec:
schedulerName: unicore-scheduler # 指定自定义调度器
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: unicore-gang-test
topologyKey: kubernetes.io/hostname
由于测试集群只有三个 worker 节点,可以看到,所有 pod 都保持 pending 状态,符合预期:
# kubectl get pod
NAME READY STATUS RESTARTS AGE
unicore-gang-test-5d95486756-6rxmr 0/1 Pending 0 2m13s
unicore-gang-test-5d95486756-gkmbj 0/1 Pending 0 2m13s
unicore-gang-test-5d95486756-gvfpk 0/1 Pending 0 2m13s
unicore-gang-test-5d95486756-mgwg5 0/1 Pending 0 2m13s
看一下 log,重要的 log 在这里:
gang.go:213] Permit found not enough gang test's pod unicore-gang-test-5d95486756-gkmbj, 2 waiting + 0 permitted + 0 running + 1 < 4 available needed
可以看到只有三个 pod 进入到了 permit 阶段,小于设置的4个,所以全部被拦在 permit 阶段外,不会被 bind。